Deep Learning을 하다보면 가장 많이 접하게 되는 단어가 Encoder와 Decoder이다.
Deep Learning을 시작한 이후로, 저 두 단어의 진정한 의미를 생각해본적 없고, 그냥 문자 그대로 받아들이고 있었다.
하지만 Transformer며 BERT며 GPT며 하는 것들에 항상 등장하는 저 단어들의 진정한 의미를 모르고 논문을 읽다보니 항상 찝찝한 마음이 남아있었다.
Encode의 사전적 의미는, “암호화하다”이고 Decode는 반대로 “복호화하다” 이다. Encoder와 Decoder는 그럼 “암호화 하는 기계”, “복호화 하는 기계”가 될 것이다. 그렇다면 도대체 무엇을 암호화하고 복호화하는 것일까?
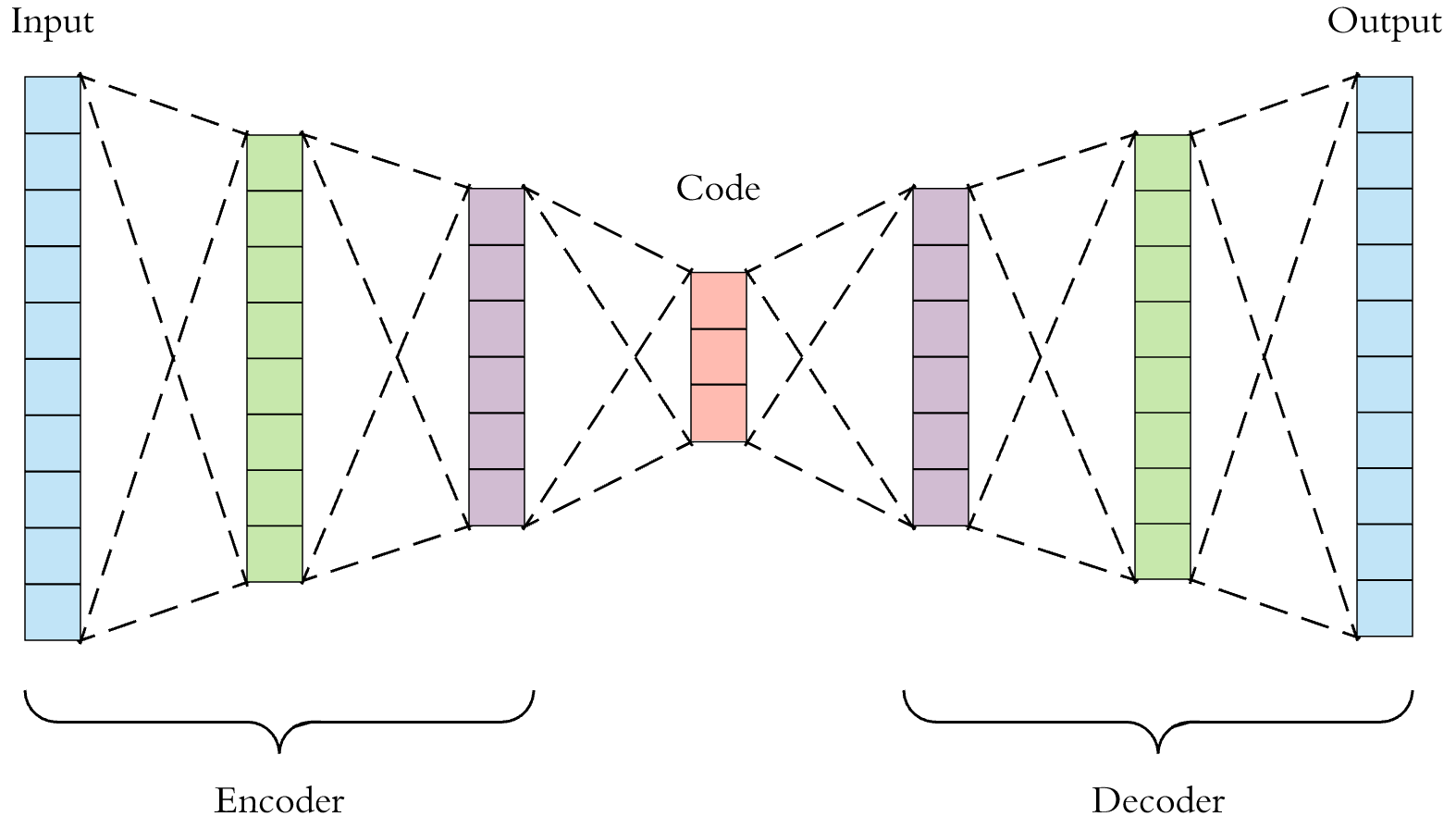
위의 그림은 Autoencoder의 모형이다. 가장 왼쪽 Encoder의 첫번째 부분에서 Input을 받아 몇단계 처리를 거치며, 점점 노드 수를 줄여가고 있다.
Input을 인간의 언어(자연어)라고 했을때, 이를 컴퓨터가 처리하려면 컴퓨터가 이해할 수 있도록 바꿔 주어야 한다.
이때 가장 쉬운 방법은 일반적으로 One-hot vector을 이용하는 방법인데, One-hot vector의 경우 처리하려는 단어의 크기에 비례해서 차원이 커지기 때문에, hidden 층으로 데이터를 넘기면서 차원을 축소해 줄 필요가 있다.
이때 hidden층에서 표현된 단어들은 각층의 가중치와 연산이 되어, 인간은 이해할 수 없는 숫자들로 이루어져 있다.(이를 단어의 분산 표현이라고 한다.)
즉 이 과정이 바로 Encoding이다. 자연어를 인간은 알아볼 수 없지만, 컴퓨터는 알아볼 수 있도록 “암호화” 한 것이다.
Decoder는 이와 완전히 반대의 과정이 된다. Encoder를 거치며 암호화 되어 hidden 층에 저장되어 있는 Input을, 다시 인간이 알아볼 수 있도록 점점 원상복구 시켜나가는 과정이다.
결국 Encoder와 Decoder를 사용하는 이유는 다음과 같다.
위에서 잠깐 언급했듯이 인간의 언어를 벡터로 표현하려면 엄청난 고차원이 벡터가 필요하다.
이를 Encoder를 통해 차원을 축소하면, 핵심 정보만 담고 있는 Dense Vector(밀집벡터)로 변환할 수 있다. 이는 컴퓨터의 연산을 줄여주게 되어, 모델의 학습효율을 높일 수 있게 된다.